Solr导入mysql的数据
如何安装
安装教程
导入数据前准备
我准备相关资料时候,在许多教程中都涉及到需要先将solr的jar包放到web项目下去。这里的话我们也按照相同的步骤去操作。
配置Solr的Jar包以及Mysql驱动包
solr8113dist_6">1.1、将solr-8.11.3\dist下的两个包进行移动
solr-dataimporthandler-8.11.3.jar
solr-dataimporthandler-extras-8.11.3.jar
移动到solr-8.11.3\server\solr-webapp\webapp\WEB-INF\lib目录下
mysqlconnect_14">1.2、将mysql-connect包也移动到该位置
这里就不做具体的版本说明了,我的版本是:
mysql-connector-java-8.0.29.jar
1.3、重启Solr项目
当我们将上面步骤完成后,我们这个时候需要将Solr项目进行重启。
配置xml
以上操作都完成后,这个时候我们就准备配置xml。
2.1、第一步我们需要创建核心
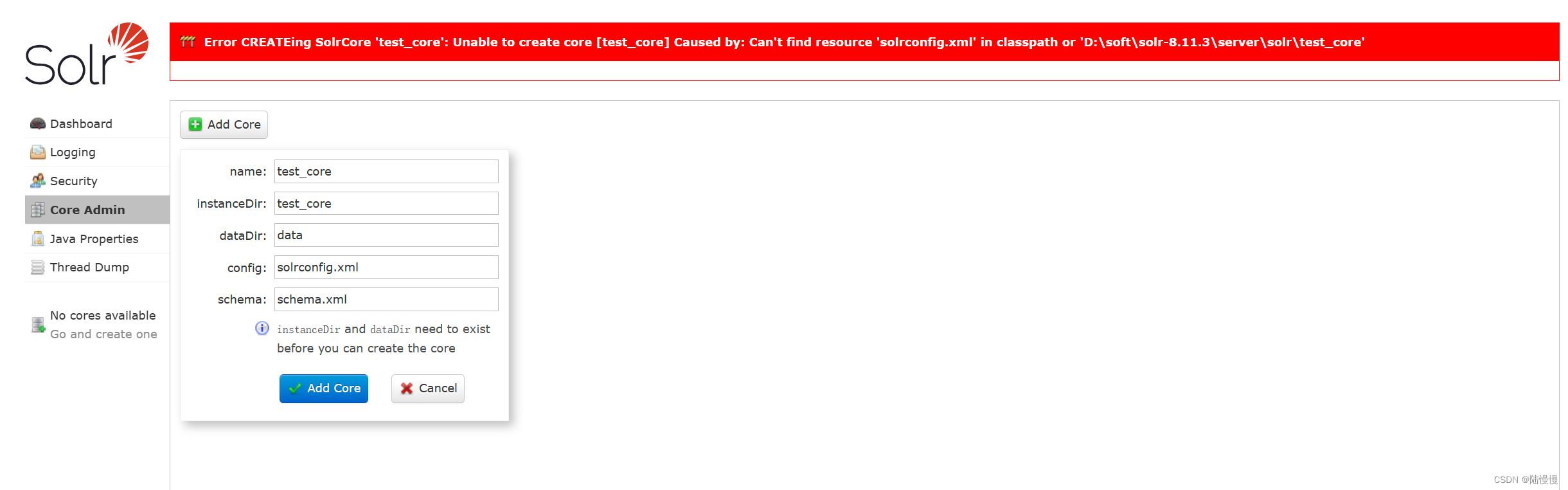
我们在这个时候会发生报错,但是没关系。虽然报错但是core的文件夹会创建成功,这时候我们根据报错文件路径将
solr-8.11.3\server\solr\configsets_default下的conf文件夹复制到我们创建的core路径下面
需要注意!!!在Rockylinux下文件路径大致不变,但是文件夹有点区别。
复制后再次点击Add Core会显示成功。
2.2、第二步修改xml(这里是结合19年的教程)
在我们刚才复制过来啊的conf文件夹中存在一个文件solrconfig.xml。我们需要对这个文件修改。
在<requestHandler name="/select" class="solr.SearchHandler">之上添加如下代码:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
2.3、 创建data-config.xml并添加配置
在conf的目录下创建data-config.xml。并添加如下内容,这里需要注意,下面的配置是你所在的数据位置连接密码和账号,不要直接复制过去不更改。
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource driver="com.mysql.cj.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/tc_reading_competition_cq" user="root" password="1101165230" encoding="UTF-8" />
<document>
<entity name="appuser" pk="id" query="select id,name,school_name from tc_applet_user where school_name is not NULL">
<field name="id" column="id" />
<field name="name" column="name" />
<field name="school_name" column="school_name" />
</entity>
</document>
</dataConfig>
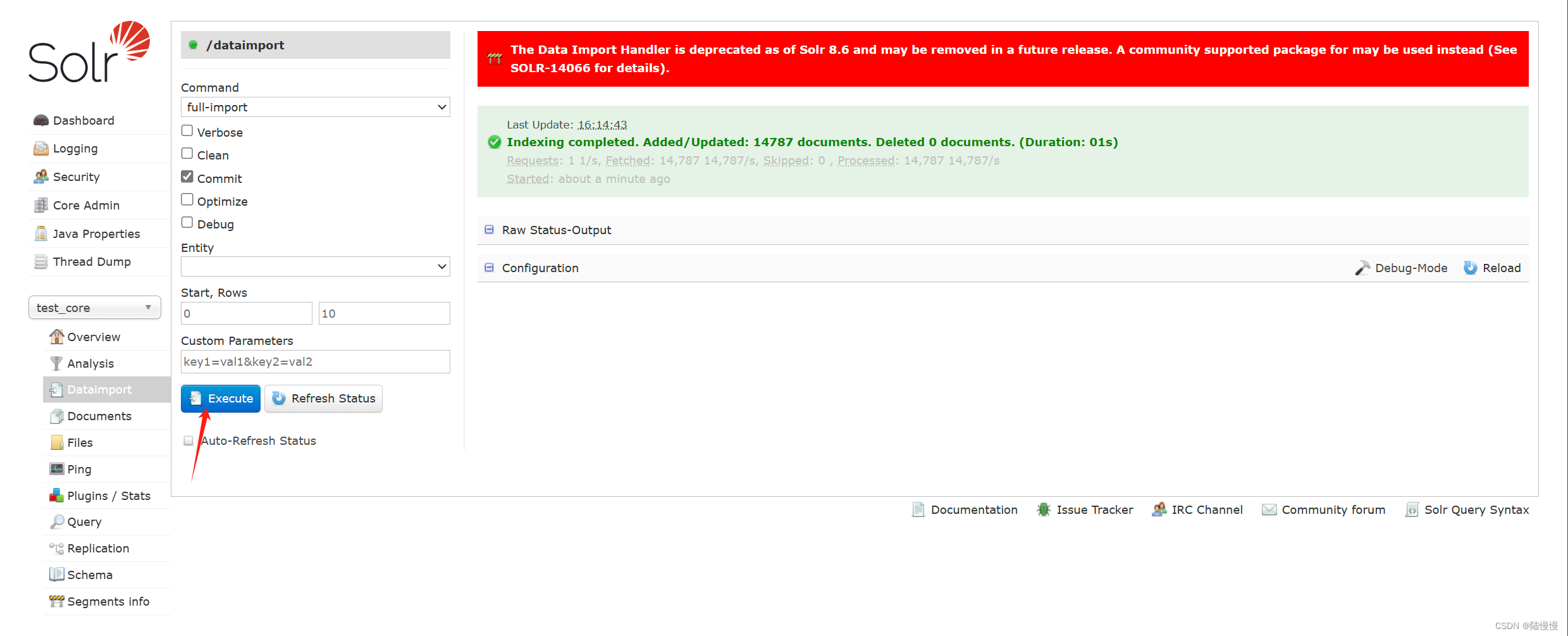
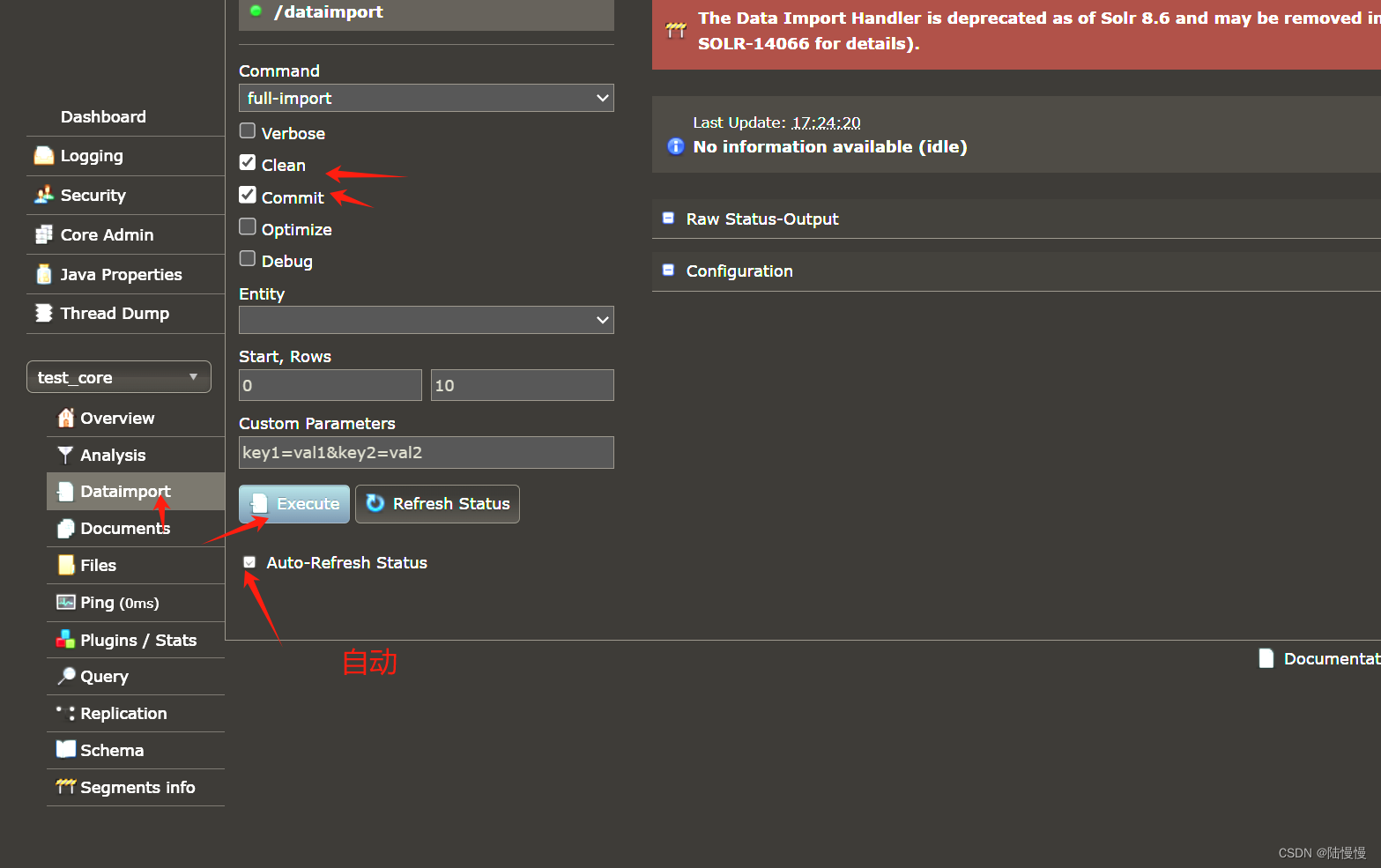
重启并导入数据
重新启动后点击这里将数据导入进来。
添加Field
如果我们按照上面的步骤导入数据的话,我们只能在Query中查询到数据的id,因为我们还没有在Solr中添加字段,添加字段的话,我们可以在xml中配置(不推荐),我推荐通过Schma去添加
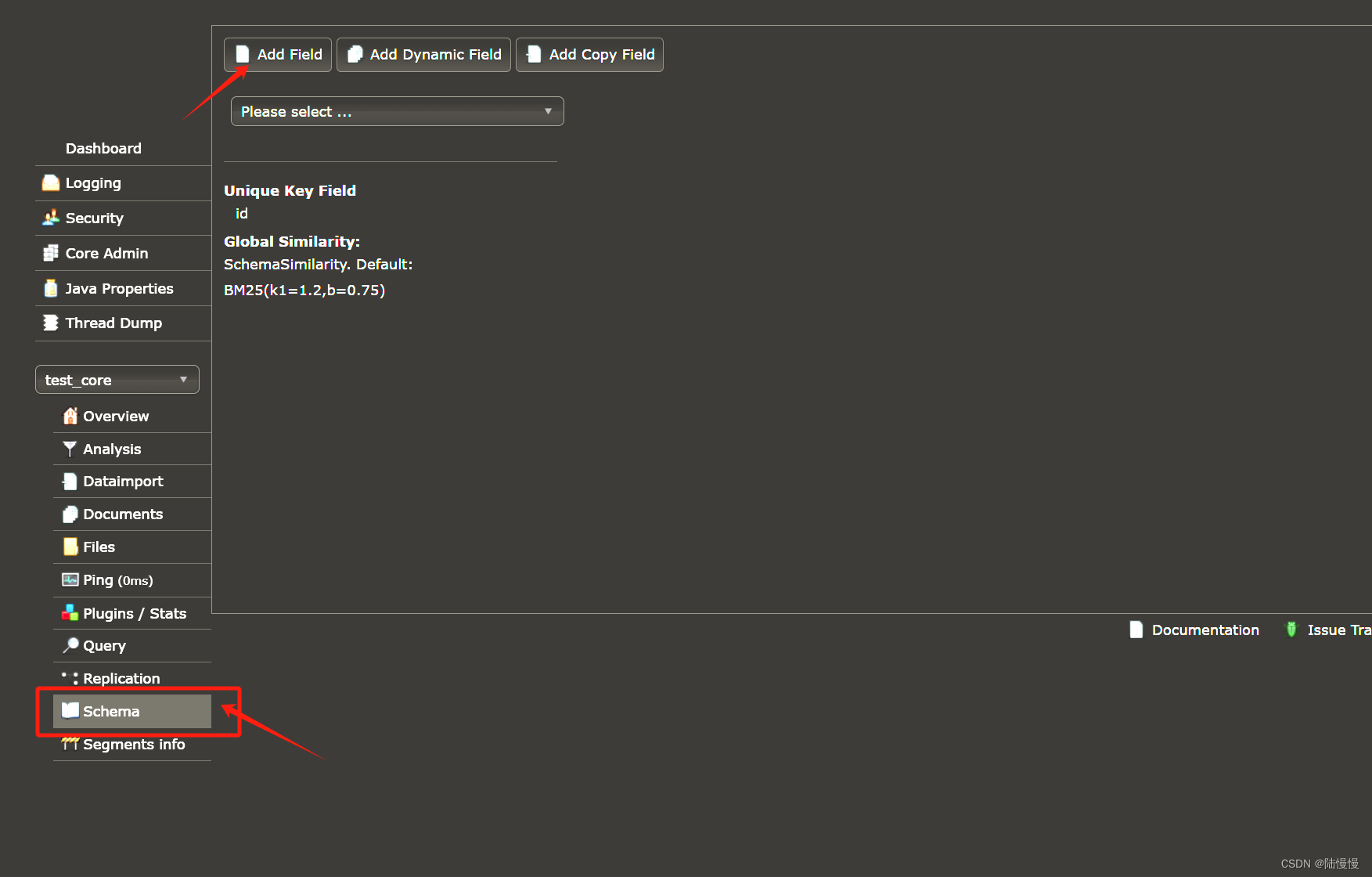
在这里我们将我们要用到的name以及school_name添加进来,并重新导入。
推荐文档
Solr导入MySQL中的数据
安装Solr以及安装分词器